語音逐字稿軟體使用比較 — Vocol.ai 與雅婷逐字稿
今天我想來分享工作效率化的工具嘗試心得。
在 CMoney,我們每個月會有 1~2 波易用性測試或訪談,視研究的題目多寡、我們訪談的時長會從 30~90 分鐘不等,UX Designer 會在事後花費一倍多的時間寫成逐字稿並提取有價值的資訊,這是個可觀的時間,我們希望透過市面上的 AI 工具來節省此方面的心力,這有機會降低研究執行的門檻進而增加更多執行頻率、幫助我們更加理解使用者;另一方面,我也希望有個工具來代替我撰寫會議或招募電話面試筆記。
雅婷逐字稿是台灣知名的語音辦識軟體,Vocol.ai 則是我在尋找 Otter.ai ( 能整合進 Google Meet / Zoom ) 支援中文辨識的競品時,意外找到的新產品。
我主要的測試對象是 Vocol.ai,雅婷則為部分情境的對照組。以下是我的觀察:
精準度
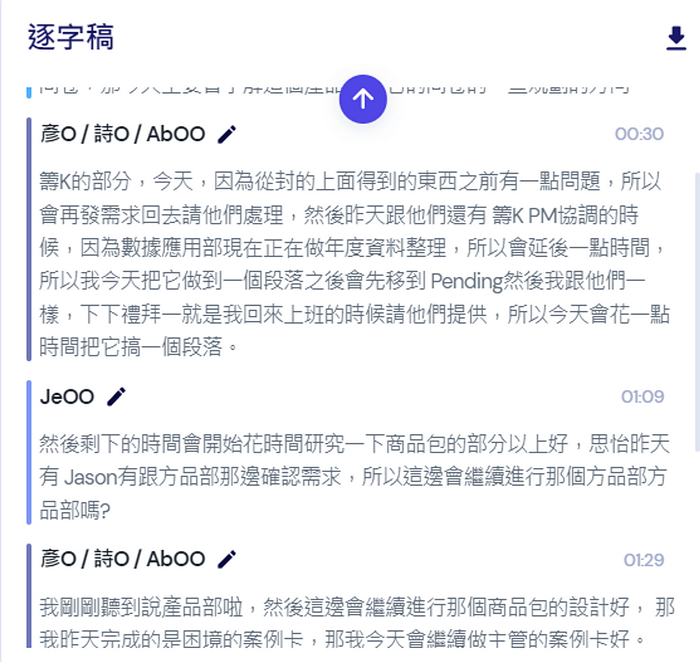
圖一是一個長達一小時的訪談,右下角是語音辦識後的逐字稿,左下則是 AI 判斷出的重點,圖二則是我們日常的一次 Daily Standup 會議。


Vocol.ai 的斷句精準度較高
以語音辦識而言,Vocol.ai 的確較雅婷精準一些 — 下面 2 張圖是兩者對同一段語音的辨識,可以看到同樣的是我”刻意放慢速度”說的一段話,雅婷的斷句、分段稍微怪了點。


Vocol.ai 容易把多人合併成一人
Vocol.ai 更容易發生把 2、3 個講話者說的話視為同一人的發言 — 明明音色 / 性別都不一樣也有間隔 2 秒鐘,仍容易認為同一人。對照組的雅婷仍有不合理的斷句,但至少不同人說話是區分得出來的。


人工修正彈性
兩個軟體都會為講話者會自動上編號,而使用者 ( 我 ) 則能為他們命名。
這裡的悲劇是 — 因為Vocol.ai 容易發生把 2、3 個講話者說的話視為同一人的發言。而當下圖 ( 01:29 ) 三者之一再次說話時,Vocol.ai 無法把他視為獨立的一次對話。也就是說,當三位講話者的說話內容被合併在一起時,我無法在後面的段絡將他們分開,這對逐字稿的結果會造成誤導,使用者終究得回來聽語音。
AI 報告
Vocol.ai 能幫我們判斷整個錄音中的各個時間區段的談話主題,以讓我們快速跳到我們需要資訊的段落。以訪談那次它會這樣幫我們摘要 :
本文主要討論了網友對於網紅消費行為的看法和經驗。訪問者問及對方對於網紅商品的消費體驗和付費訂閱的看法,對方表示消費體驗不好是不購買的主要原因之一,而付費訂閱需要考慮內容是否有時效性和價值等因素。
網紅影響力:品牌力與實際價值的影響
這段對話主要是討論對於網紅的消費行為,其中訪問者問及對方在美股的工作內容,並詢問對方最近是否有付費購買網紅的產品,對方回答是購買Peta哥哥的乳清,並解釋自己對網紅的信任度和實際價值是購買產品的主要考量因素。此外,對方也提到自己對健身的興趣和學習,以及網紅對自己帶來的價值和影響。
00:00:00->00:06:38網紅互動:訂閱、留言、付費與回覆
本段摘要描述了一位網友與網紅的消費互動經驗。網友表示自己大部分時間是潛水仔,但有問題時會留言詢問,並且對於網紅回覆與否沒有太大的期望。除此之外,網友也曾與另一位網紅進行過互動,但只是因為好奇而留言,並且得到了快速的回覆。網友也表示有考慮付費訂閱某些網紅的內容,但價格與內容的價值仍需考量。最後,網友也提到自己有觀看直播,但並不會經常進行互動。
00:06:38->00:13:06
而我們的 Standup meeting 則因為時間較短所以被總結為一段 :
工作進度及討論紀錄
在這段摘要中,討論了不同的專案進度和任務。其中包括報告、問卷、需求回饋、產品設計、行銷和視覺回饋等。此外,還提到了可能會有案子過來的可能性和需要同步的方向。最後,總結了這段討論並感謝了參與者。 00:00:02->00:03:57
手機錄音支援
Vocol.ai 雖沒有 APP 版,但其網站能在手機上開啟做錄音;雅婷則有自己的 Native APP,錄音的檔案傳輸的品質更穩定一些。
總結
由於 Vocol.ai 免費試用的情況下能支援一次 60 分鐘的影音檔轉檔,優於雅婷 ( 限 20 分鐘內 )。且還有最想試的 Google Meeting 錄音逐字稿功能還未體驗到 ( 很關心它對視覺會議連線品質的影響 ),我會繼續嘗試。
目前我認為它相對競品的優點在於 — 支援混和中英的辨識、且 AI 摘錄重點的功能、斷句較合理;缺點則是會把不同人說的話接在同一發言者底下,且手動編輯功能無法替它糾正這件事。
如果這個缺點能被克服的話,真的能作為得力助手使用,期待看到它後續的優化 !
以上是今天的分享,感謝觀看 ~








